L’intelligence artificielle pour améliorer le taux de diplomation des collèges québécois (partie 2)
Simon Bouchard
Avant votre lecture, nous vous invitons à revisiter la première partie de L’intelligence artificielle pour améliorer le taux de diplomation des collèges québécois
L’équipe d’Optania produit des algorithmes d’intelligence artificielle de qualité pour le système d’éducation québécois. Pour ce faire, une grande partie du temps de développement est alloué à la préparation de données de qualité. En effet, dans sa campagne pour une approche de l’intelligence artificielle centrée sur les données, Andrew Ng observe que la préparation des données occupe 80% du temps des développeurs en intelligence artificielle. L’autre 20% de l’effort sera essentiellement consacré à entraîner le modèle, évaluer ses performances et le déployer.

Pour plusieurs applications en intelligence artificielle, le modèle prédictif choisi n’est pas la principale source d'atténuation de la qualité des prédictions. En effet, maintenant que les modèles (réseau de neurones, gradient boosting, etc.) ont évolué en termes de performance, un effort doit être mis sur la qualité des données utilisées pour entraîner les modèles (Gil Press, 2021).
Un effet boule de neige
Une équipe de chercheurs chez Google va encore plus loin en élaborant sur le concept des cascades de données (Data Cascades). Des cascades de données arrivent lorsqu’un ou des problèmes dans une phase initiale d’élaboration de modèles prédictifs surviennent sans être corrigés avant la mise en production. Dans ce cas, l’accumulation des erreurs survenues dans les phases précédant le déploiement d’algorithmes sont vues comme étant une dette technique (Sambasivan et al., 2021). Cette dette se paiera sous forme d'incongruité dans les prédictions une fois le modèle déployé.
- L’énoncé du problème nécessitant l’application d’intelligence artificielle;
- La préparation des données : pré-traitement, collecte, étiquetage, analyse et nettoyage des données;
- La sélection de modèle;
- L’entraînement de modèle.
Un exemple de cascade de données serait un modèle prédisant les notes scolaires au secondaire entraîné sur des données historiques d’avant 2020. Le problème avec ces données serait qu’elles ne considèrent pas les conséquences de la COVID-19 sur le système de notation du système éducatif québécois. En effet, plusieurs cours au secondaire ont été offerts en mode hybride et à distance. Les épreuves ministérielles ont été annulées et certains systèmes de notation ont été complètement changés : certains groupes d’élèves n’ont pas eu de notes finales numériques et ont seulement eu une note du type «succès» ou «échec». Ainsi, les changements dans l’environnement éducatif québécois ont été si grands, qu’une équipe d’intelligence artificielle qui omet de considérer ces nombreuses variations dans la conception de leur algorithme risque d’en déployer un aux performances douteuses.
Des problèmes évitables
Différentes erreurs pouvant être commises menant à des cascades de données :
- L’entraînement d’un modèle avec des données non-bruitées et la mise en production avec des données bruitées (data drift);
- Les interactions entre le modèle entraîné dans un espace fermé et le monde réel;
- Une application inadéquate de l’expertise du domaine dans la préparation des données;
- Une mauvaise collecte de données;
- Une mauvaise documentation inter-organisationnelle.
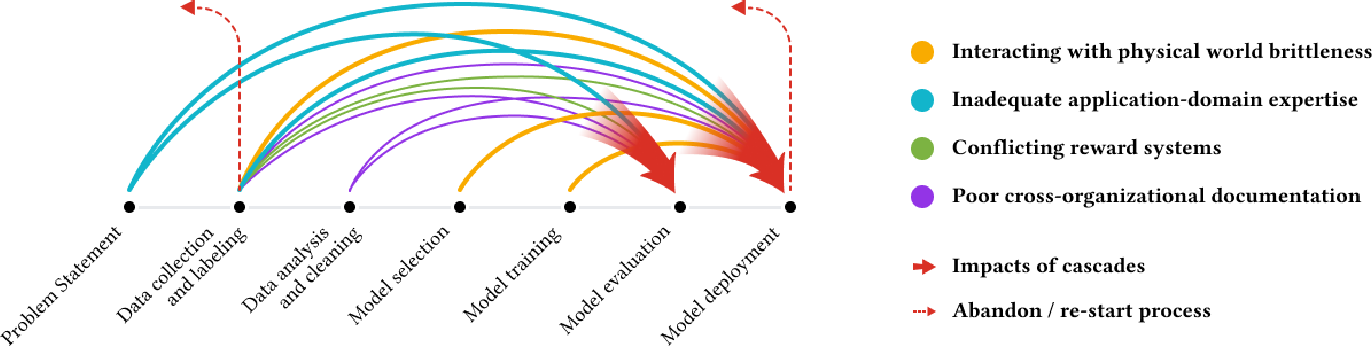 Figure 1: (Sambasivan et al., 2021)
Figure 1: (Sambasivan et al., 2021)
Ces problèmes peuvent engendrer des performances limitées lorsque le modèle est mis en production, des préjudices aux bénéficiaires des prédictions et voire même, l’abandon d’un projet d’intelligence artificielle en entier. Ainsi, il est primordial de s’attarder à chacun de ces points afin d’éviter des problèmes de prédiction au déploiement des modèles.
Évolution des produits d’IA et perspective de recherche
Comme la qualité des données se veut être une nécessité dans l’élaboration d’algorithmes de qualité, Optania met en œuvre de nombreuses stratégies afin d’arriver à cette fin. L’entreprise s’efforce de concevoir des algorithmes sains et bienveillants mettant à profit les avancées les plus récentes en statistique et en informatique. Des partenariats sont implantés avec des institutions gouvernementales et d’éducation supérieure afin de faire avancer la recherche en analyse prédictive appliquée à l’éducation :
- Projets de recherche :
- Université du Québec à Trois-Rivières. Projet en cours sur l’explicabilité des prédictions;
- Université Laval. Mémoire de maîtrise pour développer une méthode d’imputation de données manquantes adaptées aux données en éducation;
- Université du Québec à Chicoutimi. Analyse exploratoire sur les données utilisées dans la prédiction de la réussite scolaire des élèves des collèges québécois
- Soutien du Conseil national de recherches du Canada dans les activités de recherche.
De cette manière, Optania s’assure que la rigueur scientifique dans le développement de nos technologies d’intelligence artificielle respecte les plus hauts standards.
Simon Bouchard
Scientifique de données
Références
- Sambasivan, N., Kapania, S., Highfill, H., Akrong, D., Paritosh, P., & Aroyo, L. M. (2021, May).“Everyone wants to do the model work, not the data work”: Data Cascades in High-Stakes AI. In proceedings of the 2021 CHI Conference on Human Factors in Computing Systems (pp. 1-15)
- Gil Press. (2021, 16 juin ). Andrew Ng Launches A Campaign For Data-Centric AI..
Les derniers articles
Voici ce que nous avons publié récemment.



